
Overview

Problem

Technical Wall

Design Pivot
System Impact

Outcomes

Retrospective



Overview
Problem
Technical Wall
Design Pivot
System Impact
Next Steps
Profile Modeling and Transparency
Rational Logic Foundations
Establishing the foundational data blueprint for the ecosystem by solving for “confident mistakes” through staged validation and progressive logic
Overview
As Adobe expanded its ML and predictive modeling efforts, internal teams struggled to understand how profiles were stitched, how attributes were derived, and how behavioral events contributed to modeled features. Visibility across these systems was limited. As a result, debugging was slow, inconsistent, and often required heavy engineering involvement.
Internal Tooling Exploration
This work created foundational capabilities that influenced:
- Identity resolution improvements
- Early feature engineering for predictive models
- Behavioral signal quality evaluation
- Early ML-driven segmentation prototypes
- Future plans for customer-facing AI transparency tools
My Role
Primary designer responsible for defining modeling workflows, object-level metadata, quality scoring, validation mechanics, and visualization patterns. This work occurred after GA for core ingestion and schema features and ran in parallel with Query Services and early data modeling initiatives. It became the interpretability layer that tied together object structure, mapped data, and the emerging profile model.
The Problem
Identity was a black box, making behavior modeling slow, inconsistent, and hard to validate
Key Problems
Internal ML and data engineering teams needed to understand why profiles were stitched the way they were, how attributes were generated, and which behavioral events contributed to downstream predictive models. But profile formation logic was opaque, making it difficult to debug model features, evaluate attribute drift, or diagnose segmentation inconsistencies.
Teams struggled to:
- Understand which identifiers contributed to profiles
- Troubleshoot incorrect profile merges/duplicates
- Validate that attributes were complete and reliable
- Trace lineage back to source and ingestion event
Data Lineage Graph
Visualizing the flow from raw data sources to actionable features
Schema decisions define system behavior, not just data structure


Raw Data


Field mapping

Identity Cluster


Behavioral Events

Segment & Activation
Abandonment Rate Ingestion Workflow Stages
80

60
40
20
0

10%
File
Upload
25%
Schema
Mapping
45%
Review
Dataflow
60%
Enable
for Profile
70%+
Final
Ingestion
User Research Insights
- 78% User struggled to validate & resolve across the system
- 35% Abandoned complex ETL tasks
- 42% Satisfied with current workflow
The Technical Wall
Creating a shared modeling workspace where identity, attributes, and behavioral signals could be inspected and validated
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Identity rules and stitching behavior
Attribute formation across object relationships
Behavioral event contributions to profile features
Confidence indicators for features and relationships
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Primary Objectives
- Make identity formation logic understandable and inspectable
- Visualize attribute lineage and behavioral influence paths
- Improve debugging workflows and accelerate model validation
- Reduce reliance on engineering for explanation and troubleshooting
Project Constraints
- Identity logic was evolving across multiple engineering teams
- The interface needed abstraction without oversimplifying the model
- Sensitive metadata required controlled visibility and role alignment
Success Criteria
- Faster internal debugging cycles
- Improved trust in stitched profiles
- Higher reliability of machine learning features
- Clearer lineage and reasoning for behavior-driven signals
The Design Pivot
Reframing Validation
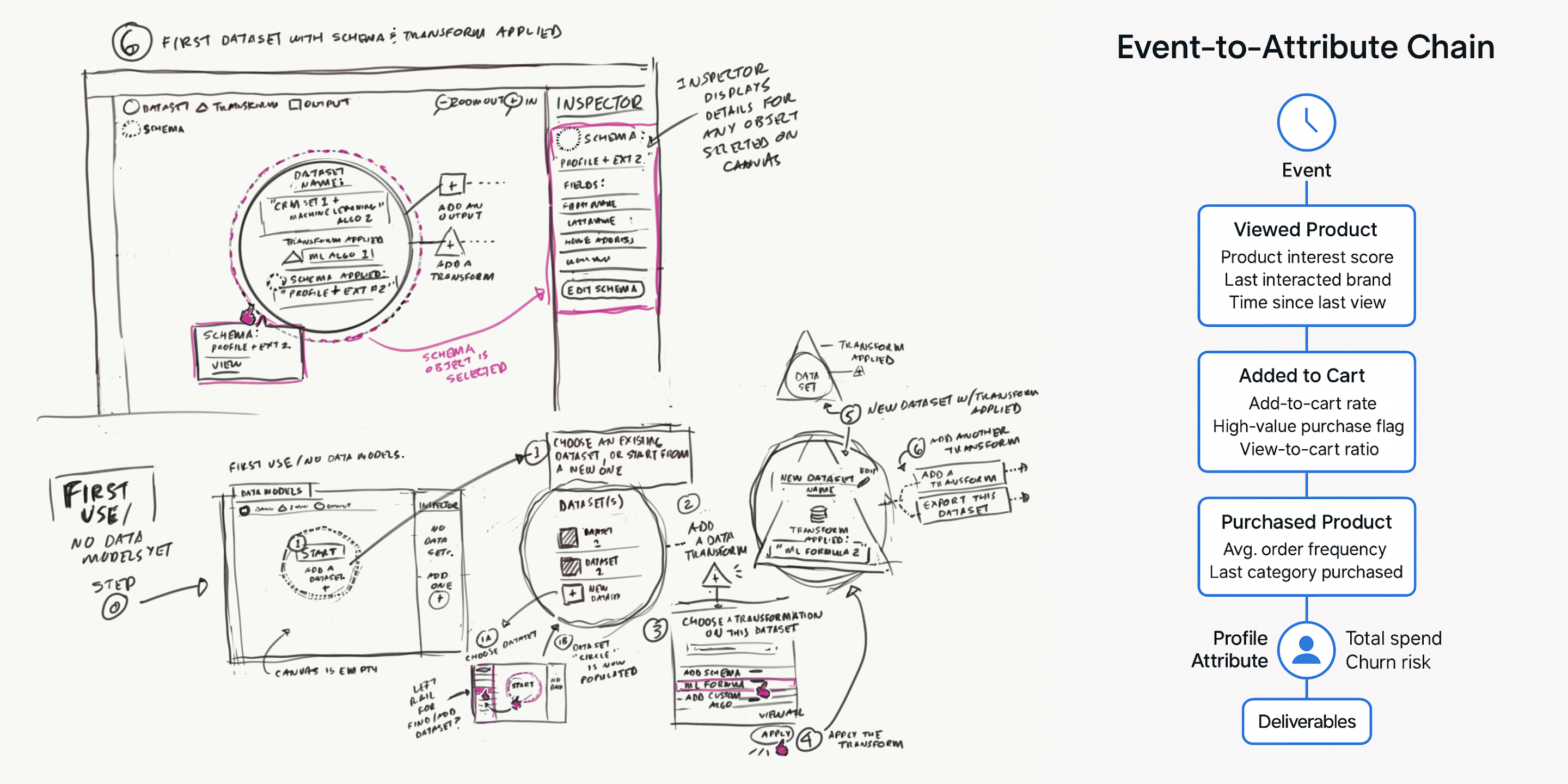
Object Orientation Exploration
Taking inventory of objects and meta data required in a schema and understanding what the user cares about most

Research & Discovery
Internal interviews uncovered a wide range of interpretation and debugging needs
Machine learning teams required clarity into how features were constructed. Data engineers needed to troubleshoot lineage breaks. Product teams needed a way to communicate identity and attribute logic across the organization.
Deliverables
Workshop personal and technical requirements
Identity workflow audit
Behavioral signal mapping
Failure-mode matrix for modeling inputs
Workshops – Personas and Technical requirements
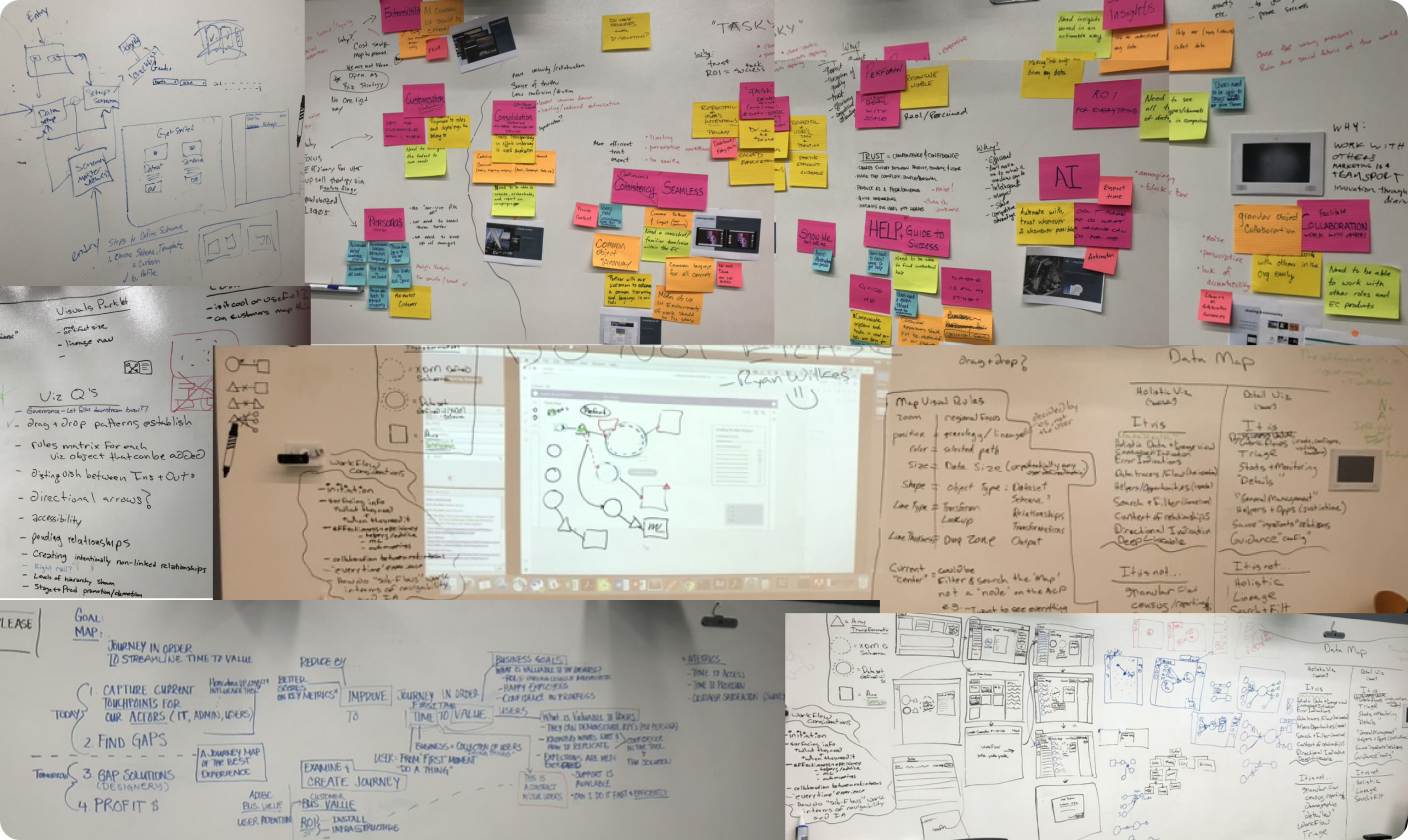
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints

Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”

Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Journey Mapping and Storyboarding


Design & Prototyping
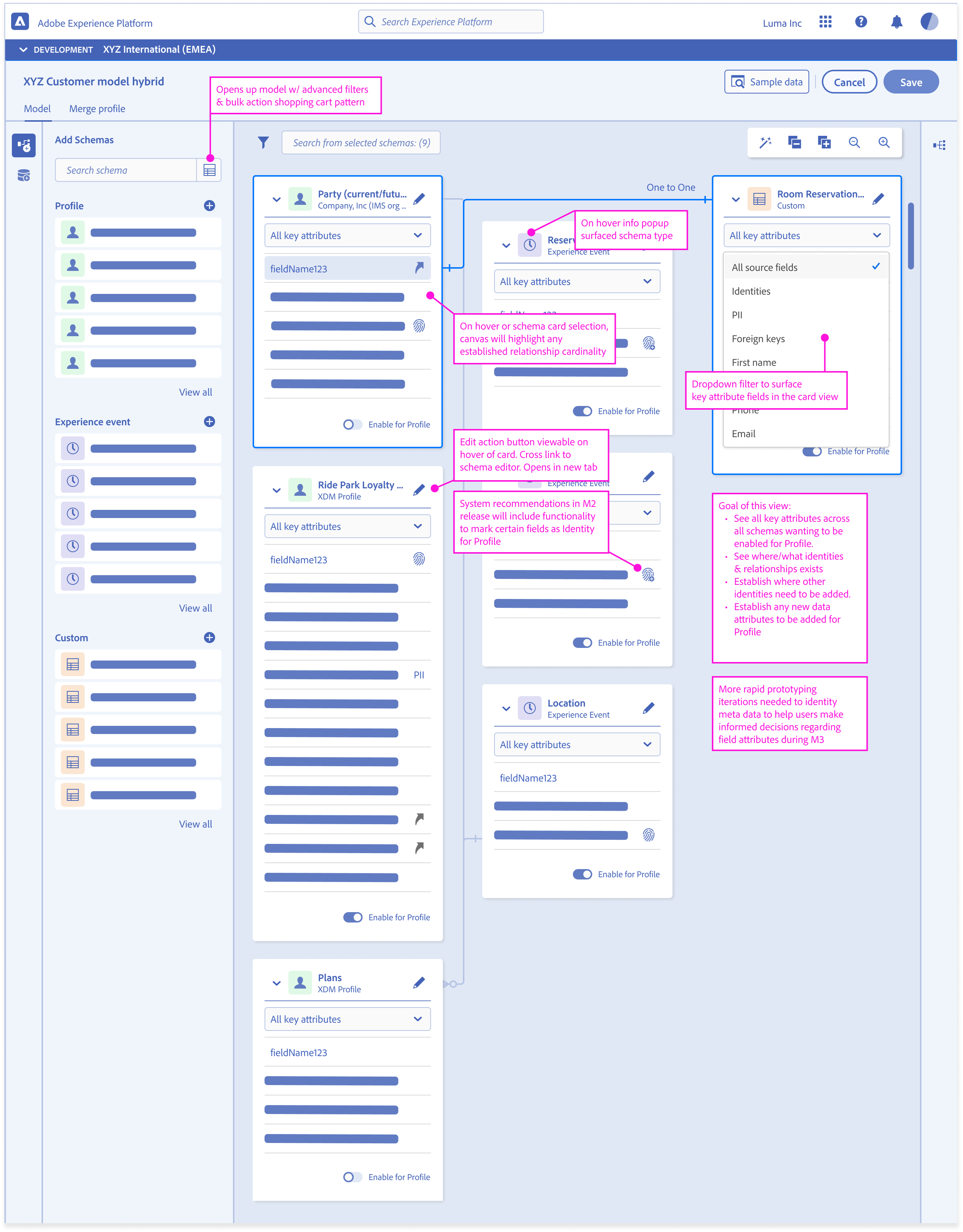
I introduced a modeling canvas that supported:
- Identity cluster exploration
- Attribute formation views
- Behavioral lineage diagrams
- Feature stability indicators
- Comparison tools for profile versions
This created a familiar interface while reducing manual effort and increasing correctness.
Deliverables
Dual-pane mapping workspace
Schema preview and glossary integration
Mapping templates and bulk ops
Suggestion layer (confidence and rationale)
Workflow Recommendations and Valid Entry Points
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
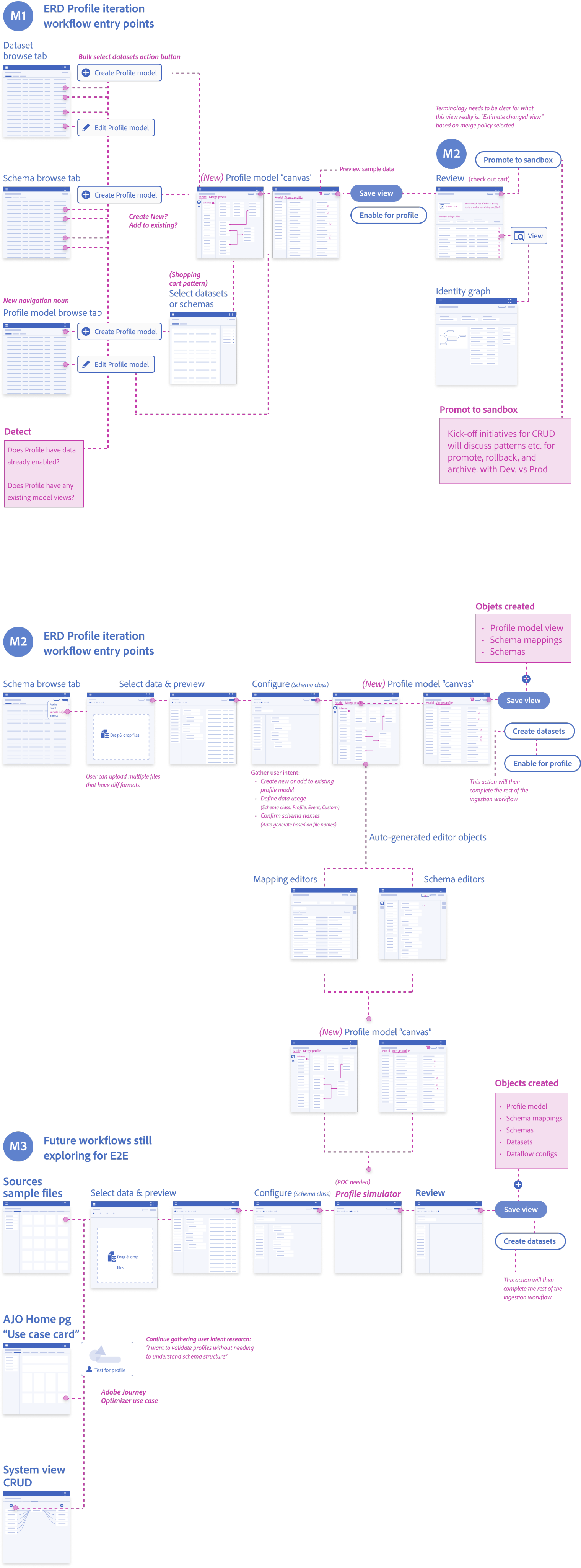
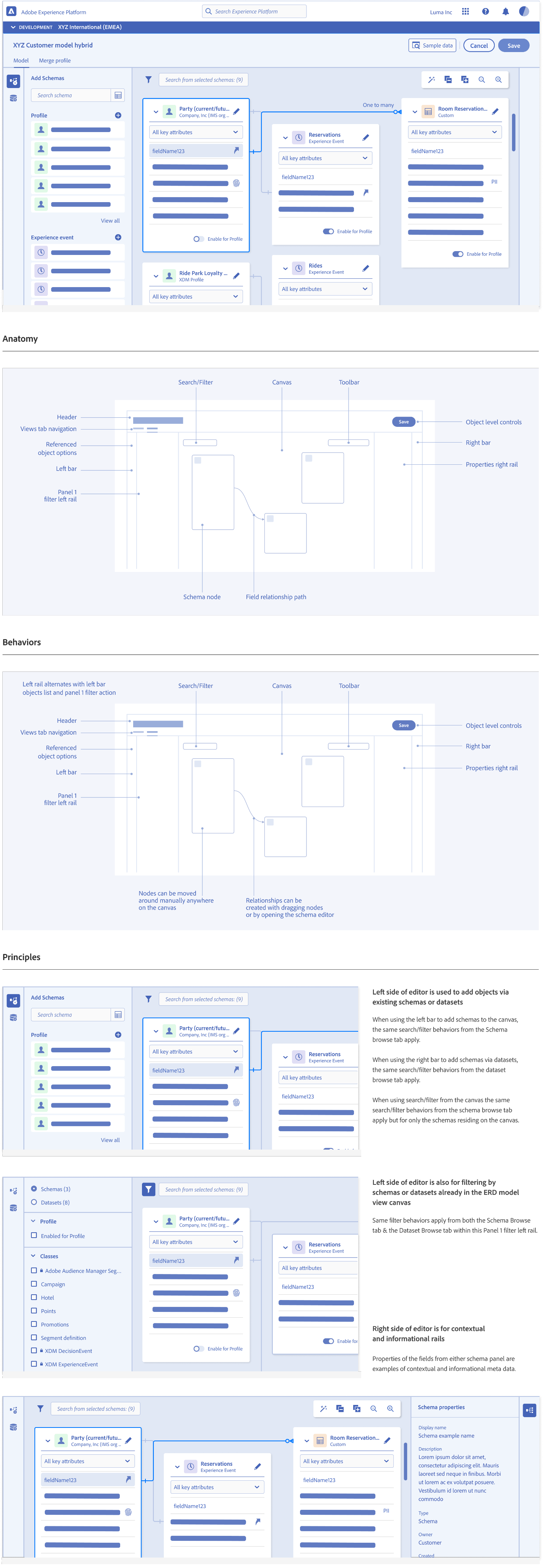
Design System Guidelines

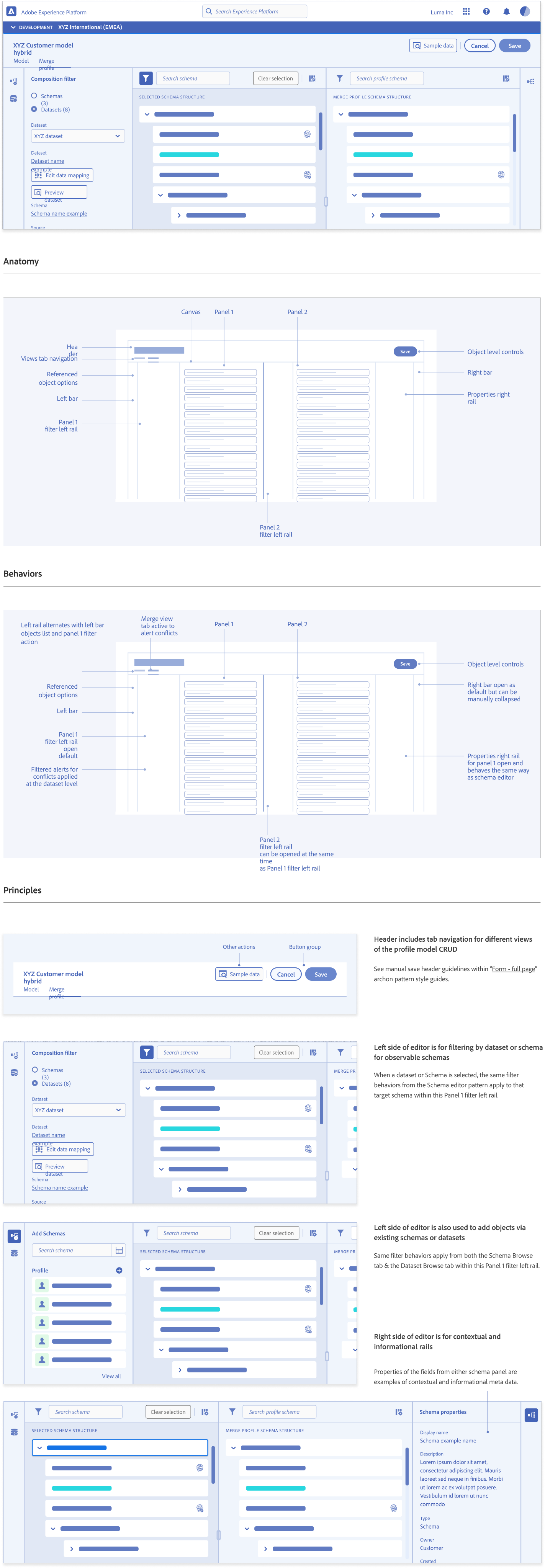
Entity Relationship Diagram (ERD) View Pattern Guidelines
Development & Testing
We evaluated real customer payloads to tune confidence thresholds and rationale messaging. Testing confirmed that explainability mattered more than automation alone. Users trusted suggestions when they understood the “why”
Deliverables
Assisted mapping trust patterns
Identity conflict alerts
Drift detection and notifcations
Low-Fidelity Prototyping
Partnered with Engineering to Refine:
- Validation rules and thresholds
- Drift detection workflows
- Feature reliability scoring
- Comparison tooling for debugging
Launch & Iteration
Stabilizing the modeling workspace and improving interpretability flows
After releasing the initial internal modeling workspace, our iteration focus was on refinement and stabilization. We incorporated feedback from ML and engineering teams to make the interface easier to interpret and to reduce friction in day-to-day debugging.
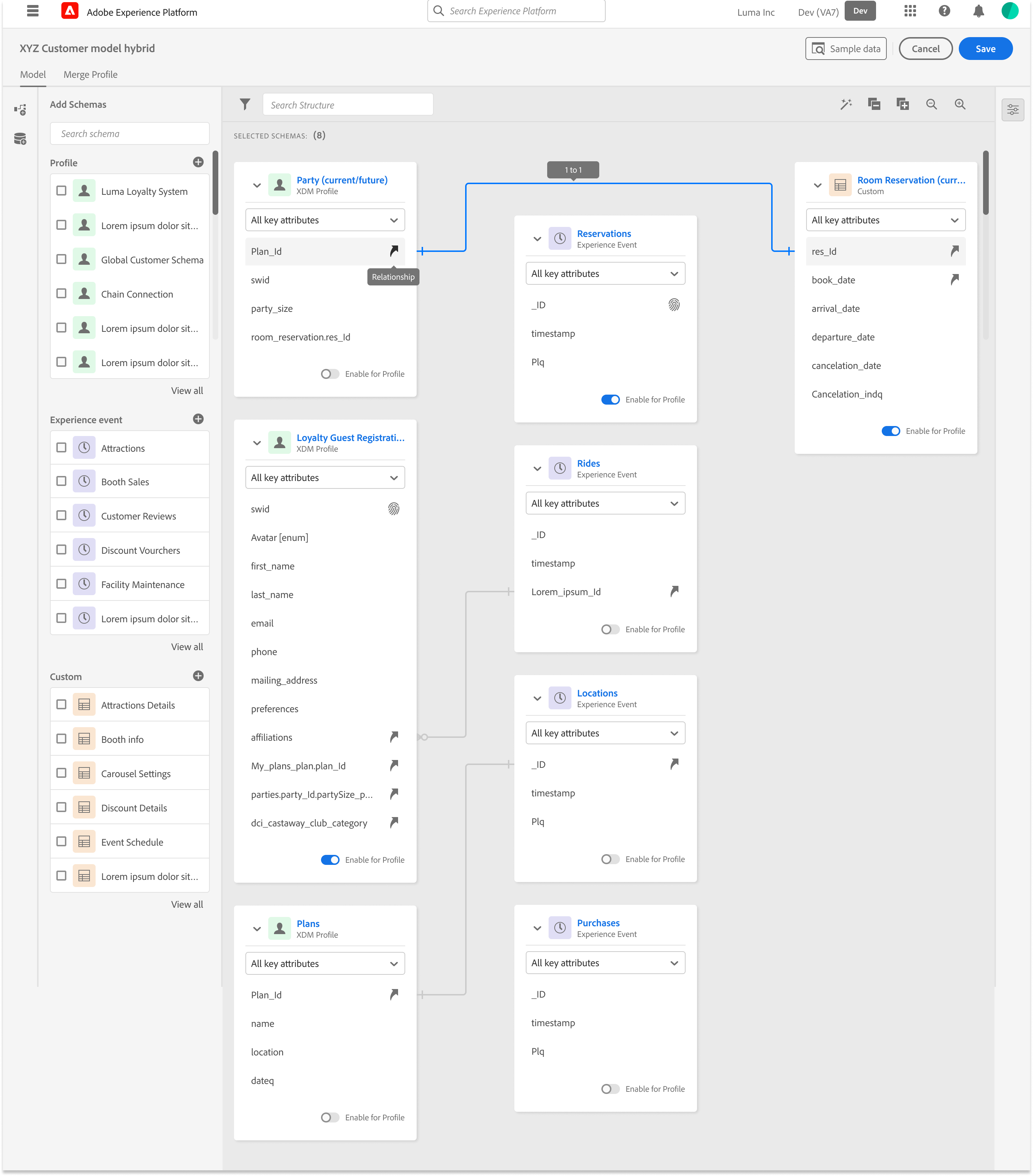
High-Fidelity Wireframes
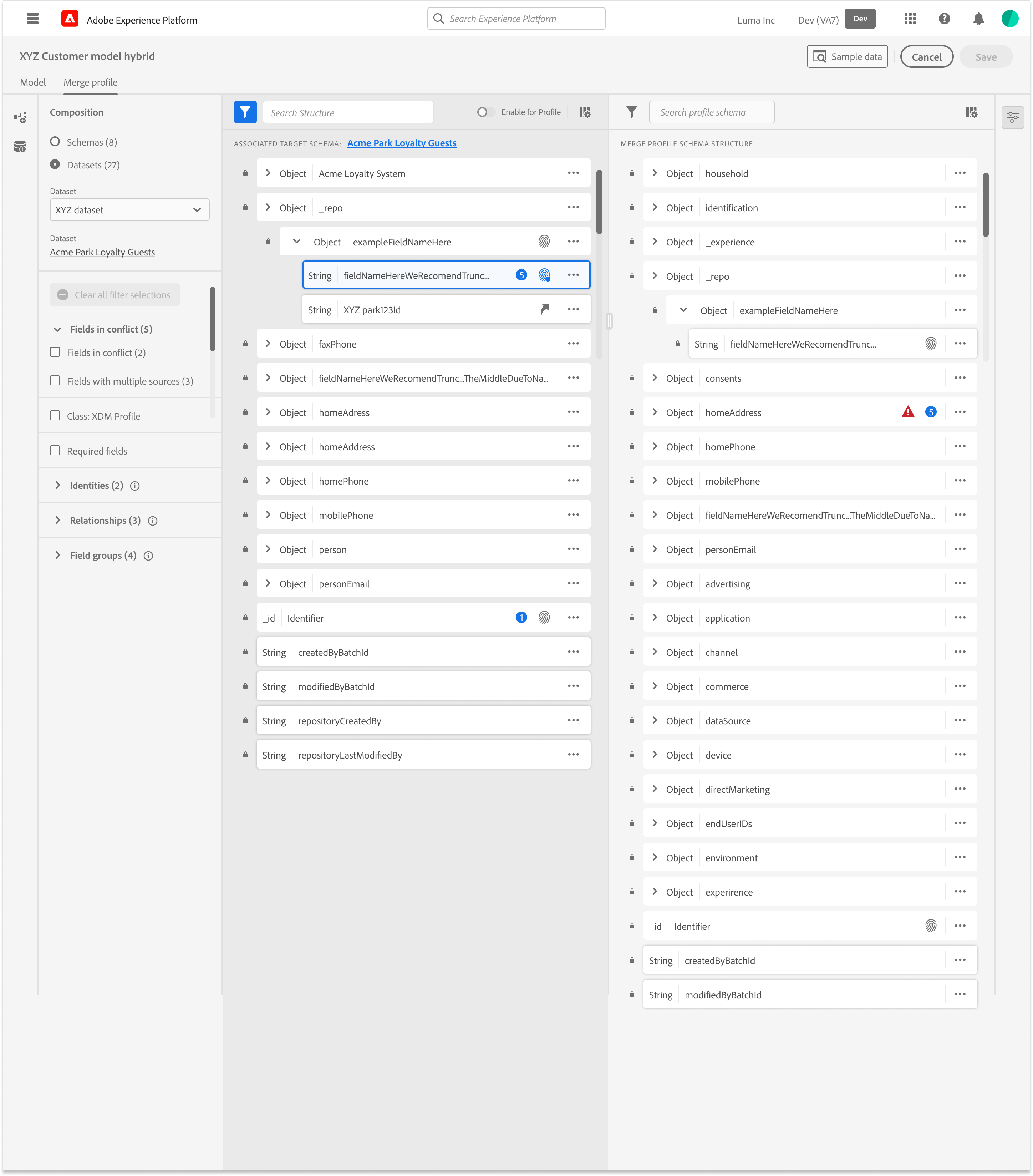
System Impact
Improved identity clarity strengthened data quality and modeling reliability
The Validation Strategy: Pipeline over UI
Instead of measuring the success by feature count, we validated the “Pipeline Readiness.” We intentionally deferred advanced UI capabilities to ensure the foundation data “handshake” was unbreakable.
Alinged Eng
A shared understanding of profile formation across engineering and ML
Accelerated Identity Conflict Resolution
Faster resolution of disputes about identity merges
Enabled Scalable AI Transparency
Clearer communication for future customer-facing AI transparency work
Next Steps & What I’d Do Differently
Future-facing opportunities that leverage the workspace foundation
What I’d Do Next
The following results were measured after the first quarter of GA, demonstrating the success of the “Pipeline Readiness” strategy
-32%
Ingestion Failure
A significant reduction in downstream errors caused by “Confident Mistakes” at the schema level
+38%
Segmentation Confidence
Increased trust from Marketing Analysts in the data being used for high-stakes campaigns
+26%
More Predictable Modeling
Improved consistency in how schemas were extended and reused across different teams.
Simulate Identity Conflicts Before Deployment
Create identity conflict simulation for ML experimentation
Benchmark & Audit Modeled Features at Scale
Integrate with Query Services to audit and benchmark modeled features
Detect Behavioral Drift Before It Impacts Models
Expand behavioral modeling previews and introduce drift comparisons
Expose Feature Influence on Outcome
Introduce feature importance and compare how event patterns drive outcomes
Surface High-Impact Behavioral Patterns
Add behavioral clustering to surface meaningful user patterns
Standardize Customer-Facing AI Explanations
Provide explanation templates for future customer-facing transparency
Validate Feature Transformations Before Commit
Explore feature generation previews to validate transformations before commit
-20%
Operational Drag
Reduced the need for manual ETL and engineering intervention to “fix” corrupted profile fragments
Related Case Studies
Let’s Work Together
Interested in collaborating on complex UI/UX challenges involving data, AI, or enterprise systems?
I’d love to explore how thoughtful design can drive clarity and business impact.

Get In Touch

About Kelli
Product Designer | AI x Data Systems
Passionate about turning complex data and AI systems into clear, trustworthy, human-centered experiences
Based in: San Francisco, CA
© 2026 Kelli Nordfelt
Overview
Problem
Technical Wall
Design Pivot
System Impact
Outcomes
Retrospective
Profile Modeling and Transparency
Rational Logic Foundations
Establishing the foundational data blueprint for the ecosystem by solving for “confident mistakes” through staged validation and progressive logic
Overview
As Adobe expanded its ML and predictive modeling efforts, internal teams struggled to understand how profiles were stitched, how attributes were derived, and how behavioral events contributed to modeled features. Visibility across these systems was limited. As a result, debugging was slow, inconsistent, and often required heavy engineering involvement.
Internal Tooling Exploration
This work created foundational capabilities that influenced:
- Identity resolution improvements
- Early feature engineering for predictive models
- Behavioral signal quality evaluation
- Early ML-driven segmentation prototypes
- Future plans for customer-facing AI transparency tools
My Role
Primary designer responsible for defining modeling workflows, object-level metadata, quality scoring, validation mechanics, and visualization patterns. This work occurred after GA for core ingestion and schema features and ran in parallel with Query Services and early data modeling initiatives. It became the interpretability layer that tied together object structure, mapped data, and the emerging profile model.
The Problem
Identity was a black box, making behavior modeling slow, inconsistent, and hard to validate
Key Problems
Internal ML and data engineering teams needed to understand why profiles were stitched the way they were, how attributes were generated, and which behavioral events contributed to downstream predictive models. But profile formation logic was opaque, making it difficult to debug model features, evaluate attribute drift, or diagnose segmentation inconsistencies.
Teams struggled to:
- Understand which identifiers contributed to profiles
- Troubleshoot incorrect profile merges/duplicates
- Validate that attributes were complete and reliable
- Trace lineage back to source and ingestion event
Data Lineage Graph
Visualizing the flow from raw data sources to actionable features
Schema decisions define system behavior, not just data structure
Abandonment Rate Ingestion Workflow Stages
80

60
40
20
0

10%
File
Upload
25%
Schema
Mapping
45%
Review
Dataflow
60%
Enable
for Profile
70%+
Final
Ingestion
User Research Insights
- 78% User struggled to validate & resolve across the system
- 35% Abandoned complex ETL tasks
- 42% Satisfied with current workflow
Raw Data

Customer Database
PostgreSQL
Web Analytics
Clickstream data
Mismatch fields
Mobile App Events
Firebase
Offline
Internal data lake
Mismatch fields


Field mapping
Customer Database
PostgreSQL
Web Analytics
Clickstream data
Duplicate IDs
Mobile App Events
Firebase
Offline
Internal data lake
Duplicate IDs
Identity Cluster
Identity Resolution
Email + Device ID
Target Errors
User Profiles
Unified customer view
Anonymous Tracking
Cookie-based IDs
Behavioral Events
Page Views
Navigation patterns
Product Interactions
Clicks, searches
Purchases
Transaction events
Offline
Internal data lake

Modeled Features

Customer LTV
Lifetime value score
Churn Risk
Probability 0-1
Product Affinity
Recommendation scores
Engagement Score
Activity index
Segment & Activation
High-Value Customers
LTV > $10
Warning
Churn Risk Cohort
Risk > 0.7
Warning
Product Affinity
Affinity segments
Warning
Re-engagement Targets
Low engagement score
Warning
The Technical Wall
Creating a shared modeling workspace where identity, attributes, and behavioral signals could be inspected and validated
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Identity rules and stitching behavior
Attribute formation across object relationships
Behavioral event contributions to profile features
Confidence indicators for features and relationships
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Primary Objectives
- Make identity formation logic understandable and inspectable
- Visualize attribute lineage and behavioral influence paths
- Improve debugging workflows and accelerate model validation
- Reduce reliance on engineering for explanation and troubleshooting
Project Constraints
- Identity logic was evolving across multiple engineering teams
- The interface needed abstraction without oversimplifying the model
- Sensitive metadata required controlled visibility and role alignment
Success Criteria
- Faster internal debugging cycles
- Improved trust in stitched profiles
- Higher reliability of machine learning features
- Clearer lineage and reasoning for behavior-driven signals
The Design Pivot
Reframing Validation
Object Orientation Exploration
Taking inventory of objects and meta data required in a schema and understanding what the user cares about most
Research & Discovery
Internal interviews uncovered a wide range of interpretation and debugging needs
Machine learning teams required clarity into how features were constructed. Data engineers needed to troubleshoot lineage breaks. Product teams needed a way to communicate identity and attribute logic across the organization.
Deliverables
Workshop personal and technical requirements
Identity workflow audit
Behavioral signal mapping
Failure-mode matrix for modeling inputs
Workshops – Personas and Technical requirements
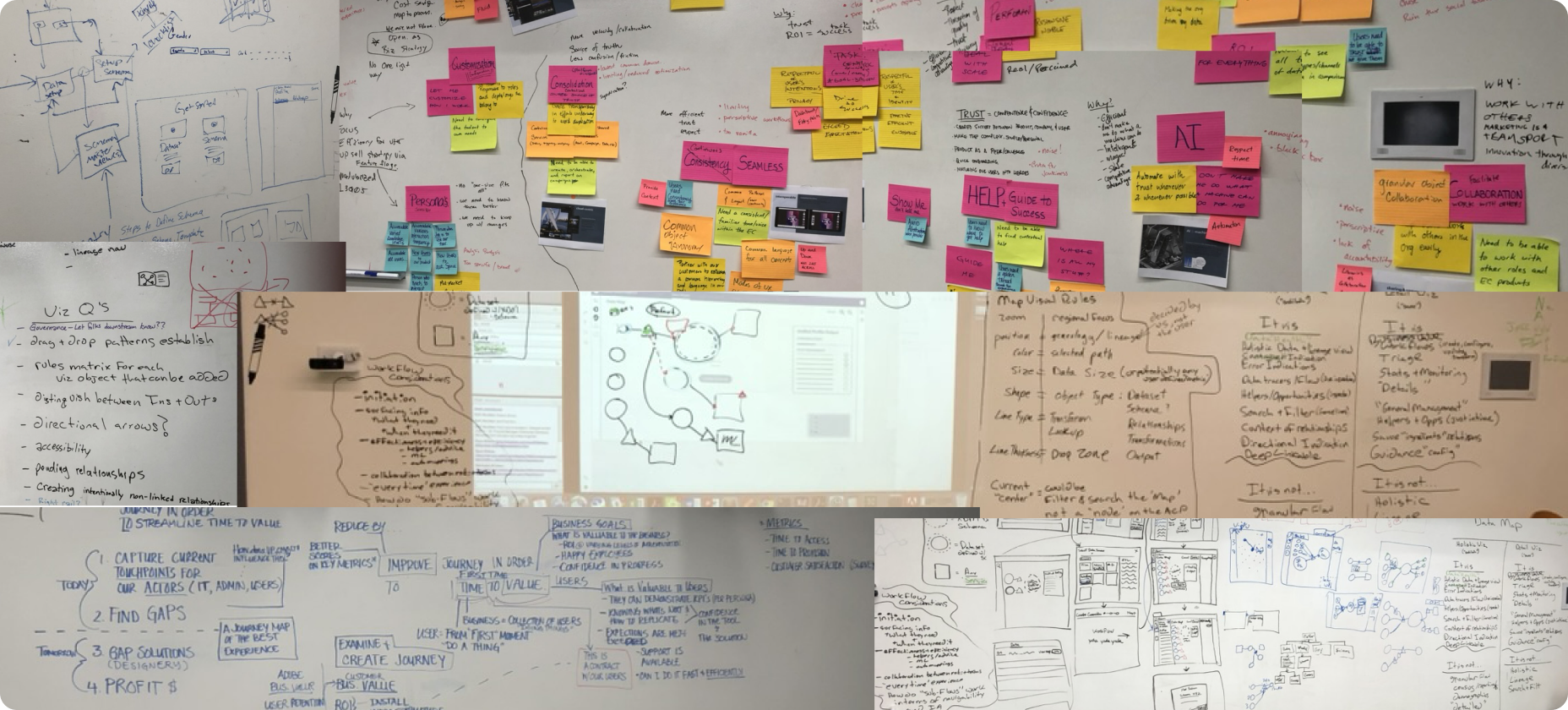
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Journey Mapping and Storyboarding
Design & Prototyping
I introduced a modeling canvas that supported:
- Identity cluster exploration
- Attribute formation views
- Behavioral lineage diagrams
- Feature stability indicators
- Comparison tools for profile versions
This created a familiar interface while reducing manual effort and increasing correctness.
Deliverables
Dual-pane mapping workspace
Schema preview and glossary integration
Mapping templates and bulk ops
Suggestion layer (confidence and rationale)
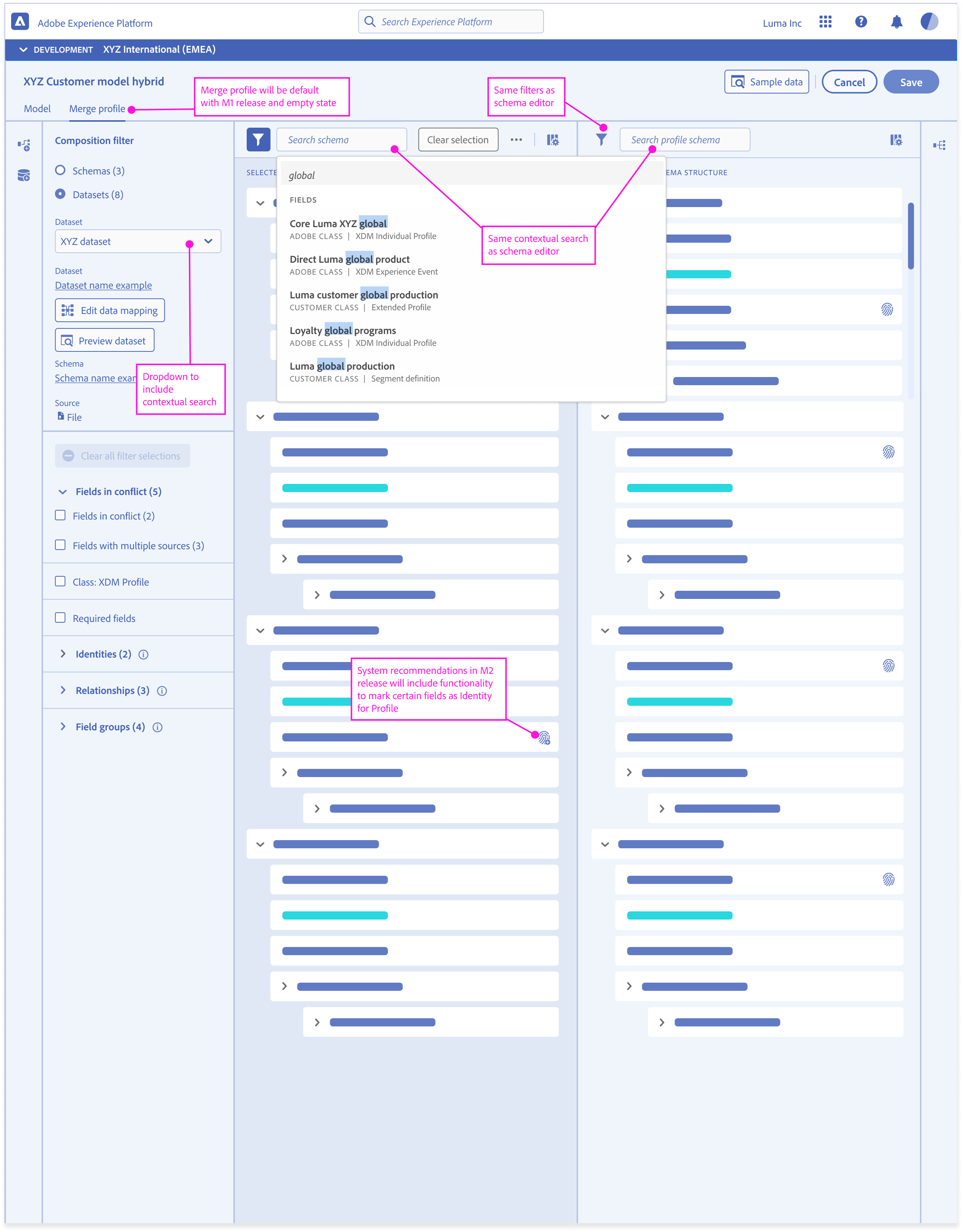
Workflow Recommendations and Valid Entry Points
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
Design System Guidelines
Entity Relationship Diagram (ERD) View Pattern Guidelines
Development & Testing
We evaluated real customer payloads to tune confidence thresholds and rationale messaging. Testing confirmed that explainability mattered more than automation alone. Users trusted suggestions when they understood the “why”
Deliverables
Assisted mapping trust patterns
Identity conflict alerts
Drift detection and notifcations
Low-Fidelity Prototyping
Partnered with Engineering to Refine:
- Validation rules and thresholds
- Drift detection workflows
- Feature reliability scoring
- Comparison tooling for debugging
Launch & Iteration
Stabilizing the modeling workspace and improving interpretability flows
After releasing the initial internal modeling workspace, our iteration focus was on refinement and stabilization. We incorporated feedback from ML and engineering teams to make the interface easier to interpret and to reduce friction in day-to-day debugging.
High-Fidelity Wireframes
System Impact
Improved identity clarity strengthened data quality and modeling reliability
Instead of measuring the success by feature count, we validated the “Pipeline Readiness.” We intentionally deferred advanced UI capabilities to ensure the foundation data “handshake” was unbreakable.
The Validation Strategy: Pipeline over UI
Enabled Scalable AI Transparency
Clearer communication for future customer-facing AI transparency work
Alinged Eng
A shared understanding of profile formation across engineering and ML
Accelerated Identity Conflict Resolution
Faster resolution of disputes about identity merges
-20%
Reduction in Debugging Cycles
25-40%%
Faster Identity Conflict Resolution
15-20%
Increase in Modeling Reliability
65-70%
Earlier Detection of Stitching Conflicts
Next Steps & What I’d Do Differently
Future-facing opportunities that leverage the workspace foundation
What I’d Do Next
The following results were measured after the first quarter of GA, demonstrating the success of the “Pipeline Readiness” strategy
Detect Behavioral Drift Before It Impacts Models
Expand behavioral modeling previews and introduce drift comparisons
Simulate Identity Conflicts Before Deployment
Create identity conflict simulation for ML experimentation
Benchmark & Audit Modeled Features at Scale
Integrate with Query Services to audit and benchmark modeled features
Expose Feature Influence on Outcome
Introduce feature importance and compare how event patterns drive outcomes
Surface High-Impact Behavioral Patterns
Add behavioral clustering to surface meaningful user patterns
Standardize Customer-Facing AI Explanations
Provide explanation templates for future customer-facing transparency
Validate Feature Transformations Before Commit
Explore feature generation previews to validate transformations before commit
Related Case Studies
Let’s Work Together
Interested in collaborating on complex UI/UX challenges involving data, AI, or enterprise systems?
I’d love to explore how thoughtful design can drive clarity and business impact.
Get In Touch
About Kelli
Product Designer | AI x Data Systems
Passionate about turning complex data and AI systems into clear, trustworthy, human-centered experiences
Based in: San Francisco, CA
© 2026 Kelli Nordfelt
Overview
Problem
Technical Wall

Design Pivot
System Impact
Next Steps
Profile Modeling and Transparency
Rational Logic Foundations
Establishing the foundational data blueprint for the ecosystem by solving for “confident mistakes” through staged validation and progressive logic
Overview
As Adobe expanded its ML and predictive modeling efforts, internal teams struggled to understand how profiles were stitched, how attributes were derived, and how behavioral events contributed to modeled features. Visibility across these systems was limited. As a result, debugging was slow, inconsistent, and often required heavy engineering involvement.
Internal Tooling Exploration
This work created foundational capabilities that influenced:
- Identity resolution improvements
- Early feature engineering for predictive models
- Behavioral signal quality evaluation
- Early ML-driven segmentation prototypes
- Future plans for customer-facing AI transparency tools
My Role
Primary designer responsible for defining modeling workflows, object-level metadata, quality scoring, validation mechanics, and visualization patterns. This work occurred after GA for core ingestion and schema features and ran in parallel with Query Services and early data modeling initiatives. It became the interpretability layer that tied together object structure, mapped data, and the emerging profile model.
The Problem
Identity was a black box, making behavior modeling slow, inconsistent, and hard to validate
Key Problems
Internal ML and data engineering teams needed to understand why profiles were stitched the way they were, how attributes were generated, and which behavioral events contributed to downstream predictive models. But profile formation logic was opaque, making it difficult to debug model features, evaluate attribute drift, or diagnose segmentation inconsistencies.
Teams struggled to:
- Understand which identifiers contributed to profiles
- Troubleshoot incorrect profile merges/duplicates
- Validate that attributes were complete and reliable
- Trace lineage back to source and ingestion event
Data Lineage Graph
Visualizing the flow from raw data sources to actionable features
Schema decisions define system behavior, not just data structure
Abandonment Rate Ingestion Workflow Stages
80

60
40
20
0

10%
File
Upload
25%
Schema
Mapping
45%
Review
Dataflow
60%
Enable
for Profile
70%+
Final
Ingestion
User Research Insights
- 78% User struggled to validate & resolve across the system
- 35% Abandoned complex ETL tasks
- 42% Satisfied with current workflow
Raw Data

Customer Database
PostgreSQL
Web Analytics
Clickstream data
Mismatch fields
Mobile App Events
Firebase
Offline
Internal data lake
Mismatch fields
Field mapping

Customer Database
PostgreSQL
Web Analytics
Clickstream data
Duplicate IDs
Mobile App Events
Firebase
Offline
Internal data lake
Duplicate IDs
Identity Cluster
Identity Resolution
Email + Device ID
Target Errors
User Profiles
Unified customer view
Anonymous Tracking
Cookie-based IDs
Behavioral Events
Page Views
Navigation patterns
Product Interactions
Clicks, searches
Purchases
Transaction events
Offline
Internal data lake
Modeled Features
Customer LTV
Lifetime value score
Churn Risk
Probability 0-1
Product Affinity
Recommendation scores
Engagement Score
Activity index
Segment & Activation
High-Value Customers
LTV > $10
Warning
Churn Risk Cohort
Risk > 0.7
Warning
Product Affinity
Affinity segments
Warning
Re-engagement Targets
Low engagement score
Warning
The Technical Wall
Creating a shared modeling workspace where identity, attributes, and behavioral signals could be inspected and validated
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Identity rules and stitching behavior
Attribute formation across object relationships
Behavioral event contributions to profile features
Confidence indicators for features and relationships
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Primary Objectives
- Make identity formation logic understandable and inspectable
- Visualize attribute lineage and behavioral influence paths
- Improve debugging workflows and accelerate model validation
- Reduce reliance on engineering for explanation and troubleshooting
Project Constraints
- Identity logic was evolving across multiple engineering teams
- The interface needed abstraction without oversimplifying the model
- Sensitive metadata required controlled visibility and role alignment
Success Criteria
- Faster internal debugging cycles
- Improved trust in stitched profiles
- Higher reliability of machine learning features
- Clearer lineage and reasoning for behavior-driven signals
The Design Pivot
Reframing Validation
Object Orientation Exploration
Taking inventory of objects and meta data required in a schema and understanding what the user cares about most
Research & Discovery
Internal interviews uncovered a wide range of interpretation and debugging needs
Machine learning teams required clarity into how features were constructed. Data engineers needed to troubleshoot lineage breaks. Product teams needed a way to communicate identity and attribute logic across the organization.
Deliverables
Workshop personal and technical requirements
Identity workflow audit
Behavioral signal mapping
Failure-mode matrix for modeling inputs
Workshops – Personas and Technical requirements
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Journey Mapping and Storyboarding
Design & Prototyping
I introduced a modeling canvas that supported:
- Identity cluster exploration
- Attribute formation views
- Behavioral lineage diagrams
- Feature stability indicators
- Comparison tools for profile versions
This created a familiar interface while reducing manual effort and increasing correctness.
Deliverables
Dual-pane mapping workspace
Schema preview and glossary integration
Mapping templates and bulk ops
Suggestion layer (confidence and rationale)
Workflow Recommendations and Valid Entry Points
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
Design System Guidelines
Entity Relationship Diagram (ERD) View Pattern Guidelines
Development & Testing
We evaluated real customer payloads to tune confidence thresholds and rationale messaging. Testing confirmed that explainability mattered more than automation alone. Users trusted suggestions when they understood the “why”
Deliverables
Assisted mapping trust patterns
Identity conflict alerts
Drift detection and notifcations
Low-Fidelity Prototyping
Partnered with Engineering to Refine:
- Validation rules and thresholds
- Drift detection workflows
- Feature reliability scoring
- Comparison tooling for debugging
Launch & Iteration
Stabilizing the modeling workspace and improving interpretability flows
After releasing the initial internal modeling workspace, our iteration focus was on refinement and stabilization. We incorporated feedback from ML and engineering teams to make the interface easier to interpret and to reduce friction in day-to-day debugging.
High-Fidelity Wireframes
System Impact
Improved identity clarity strengthened data quality and modeling reliability
The Validation Strategy: Pipeline over UI
Instead of measuring the success by feature count, we validated the “Pipeline Readiness.” We intentionally deferred advanced UI capabilities to ensure the foundation data “handshake” was unbreakable.
Enabled Scalable AI Transparency
Clearer communication for future customer-facing AI transparency work
Alinged Eng
A shared understanding of profile formation across engineering and ML
Accelerated Identity Conflict Resolution
Faster resolution of disputes about identity merges
-20%
Reduction in Debugging Cycles
25-40%%
Faster Identity Conflict Resolution
15-20%
Increase in Modeling Reliability
65-70%
Earlier Detection of Stitching Conflicts
Next Steps & What I’d Do Differently
Future-facing opportunities that leverage the workspace foundation
What I’d Do Next
The following results were measured after the first quarter of GA, demonstrating the success of the “Pipeline Readiness” strategy
Detect Behavioral Drift Before It Impacts Models
Expand behavioral modeling previews and introduce drift comparisons
Simulate Identity Conflicts Before Deployment
Create identity conflict simulation for ML experimentation
Benchmark & Audit Modeled Features at Scale
Integrate with Query Services to audit and benchmark modeled features
Expose Feature Influence on Outcome
Introduce feature importance and compare how event patterns drive outcomes
Surface High-Impact Behavioral Patterns
Add behavioral clustering to surface meaningful user patterns
Standardize Customer-Facing AI Explanations
Provide explanation templates for future customer-facing transparency
Validate Feature Transformations Before Commit
Explore feature generation previews to validate transformations before commit
Related Case Studies
Let’s Work Together
Interested in collaborating on complex UI/UX challenges involving data, AI, or enterprise systems?
I’d love to explore how thoughtful design can drive clarity and business impact.
Get In Touch
About Kelli
Product Designer | AI x Data Systems
Passionate about turning complex data and AI systems into clear, trustworthy, human-centered experiences
Based in: San Francisco, CA
© 2026 Kelli Nordfelt
Overview
Problem
Technical Wall
Design Pivot
System Impact
Next Steps
Profile Modeling and Transparency
Rational Logic Foundations
Establishing the foundational data blueprint for the ecosystem by solving for “confident mistakes” through staged validation and progressive logic
Overview
As Adobe expanded its ML and predictive modeling efforts, internal teams struggled to understand how profiles were stitched, how attributes were derived, and how behavioral events contributed to modeled features. Visibility across these systems was limited. As a result, debugging was slow, inconsistent, and often required heavy engineering involvement.
Internal Tooling Exploration
This work created foundational capabilities that influenced:
- Identity resolution improvements
- Early feature engineering for predictive models
- Behavioral signal quality evaluation
- Early ML-driven segmentation prototypes
- Future plans for customer-facing AI transparency tools
My Role
Primary designer responsible for defining modeling workflows, object-level metadata, quality scoring, validation mechanics, and visualization patterns. This work occurred after GA for core ingestion and schema features and ran in parallel with Query Services and early data modeling initiatives. It became the interpretability layer that tied together object structure, mapped data, and the emerging profile model.
The Problem
Identity was a black box, making behavior modeling slow, inconsistent, and hard to validate
Key Problems
Internal ML and data engineering teams needed to understand why profiles were stitched the way they were, how attributes were generated, and which behavioral events contributed to downstream predictive models. But profile formation logic was opaque, making it difficult to debug model features, evaluate attribute drift, or diagnose segmentation inconsistencies.
Teams struggled to:
- Understand which identifiers contributed to profiles
- Troubleshoot incorrect profile merges/duplicates
- Validate that attributes were complete and reliable
- Trace lineage back to source and ingestion event
Data Lineage Graph
Visualizing the flow from raw data sources to actionable features
Schema decisions define system behavior, not just data structure
Abandonment Rate Ingestion Workflow Stages
80

60
40
20
0

10%
File
Upload
25%
Schema
Mapping
45%
Review
Dataflow
60%
Enable
for Profile
70%+
Final
Ingestion
User Research Insights
- 78% User struggled to validate & resolve across the system
- 35% Abandoned complex ETL tasks
- 42% Satisfied with current workflow
Raw Data

Customer Database
PostgreSQL
Web Analytics
Clickstream data
Mismatch fields
Mobile App Events
Firebase
Offline
Internal data lake
Mismatch fields
Field mapping

Customer Database
PostgreSQL
Web Analytics
Clickstream data
Duplicate IDs
Mobile App Events
Firebase
Offline
Internal data lake
Duplicate IDs
Identity Cluster
Identity Resolution
Email + Device ID
Target Errors
User Profiles
Unified customer view
Anonymous Tracking
Cookie-based IDs
Behavioral Events
Page Views
Navigation patterns
Product Interactions
Clicks, searches
Purchases
Transaction events
Offline
Internal data lake
Modeled Features
Customer LTV
Lifetime value score
Churn Risk
Probability 0-1
Product Affinity
Recommendation scores
Engagement Score
Activity index
Segment & Activation
High-Value Customers
LTV > $10
Warning
Churn Risk Cohort
Risk > 0.7
Warning
Product Affinity
Affinity segments
Warning
Re-engagement Targets
Low engagement score
Warning
The Technical Wall
Creating a shared modeling workspace where identity, attributes, and behavioral signals could be inspected and validated
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Identity rules and stitching behavior
Attribute formation across object relationships
Behavioral event contributions to profile features
Confidence indicators for features and relationships
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Primary Objectives
- Make identity formation logic understandable and inspectable
- Visualize attribute lineage and behavioral influence paths
- Improve debugging workflows and accelerate model validation
- Reduce reliance on engineering for explanation and troubleshooting
Project Constraints
- Identity logic was evolving across multiple engineering teams
- The interface needed abstraction without oversimplifying the model
- Sensitive metadata required controlled visibility and role alignment
Success Criteria
- Faster internal debugging cycles
- Improved trust in stitched profiles
- Higher reliability of machine learning features
- Clearer lineage and reasoning for behavior-driven signals
The Design Pivot
Reframing Validation
Object Orientation Exploration
Taking inventory of objects and meta data required in a schema and understanding what the user cares about most
Research & Discovery
Internal interviews uncovered a wide range of interpretation and debugging needs
Machine learning teams required clarity into how features were constructed. Data engineers needed to troubleshoot lineage breaks. Product teams needed a way to communicate identity and attribute logic across the organization.
Deliverables
Workshop personal and technical requirements
Identity workflow audit
Behavioral signal mapping
Failure-mode matrix for modeling inputs
Workshops – Personas and Technical requirements
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints

Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Journey Mapping and Storyboarding
Design & Prototyping
I introduced a modeling canvas that supported:
- Identity cluster exploration
- Attribute formation views
- Behavioral lineage diagrams
- Feature stability indicators
- Comparison tools for profile versions
This created a familiar interface while reducing manual effort and increasing correctness.
Deliverables
Dual-pane mapping workspace
Schema preview and glossary integration
Mapping templates and bulk ops
Suggestion layer (confidence and rationale)
Workflow Recommendations and Valid Entry Points
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
Design System Guidelines
Entity Relationship Diagram (ERD) View Pattern Guidelines
Development & Testing
We evaluated real customer payloads to tune confidence thresholds and rationale messaging. Testing confirmed that explainability mattered more than automation alone. Users trusted suggestions when they understood the “why”
Deliverables
Assisted mapping trust patterns
Identity conflict alerts
Drift detection and notifcations
Low-Fidelity Prototyping
Partnered with Engineering to Refine:
- Validation rules and thresholds
- Drift detection workflows
- Feature reliability scoring
- Comparison tooling for debugging
Launch & Iteration
Stabilizing the modeling workspace and improving interpretability flows
After releasing the initial internal modeling workspace, our iteration focus was on refinement and stabilization. We incorporated feedback from ML and engineering teams to make the interface easier to interpret and to reduce friction in day-to-day debugging.
High-Fidelity Wireframes
System Impact
Improved identity clarity strengthened data quality and modeling reliability
The Validation Strategy: Pipeline over UI
Instead of measuring the success by feature count, we validated the “Pipeline Readiness.” We intentionally deferred advanced UI capabilities to ensure the foundation data “handshake” was unbreakable.
Enabled Scalable AI Transparency
Clearer communication for future customer-facing AI transparency work
Alinged Eng
A shared understanding of profile formation across engineering and ML
Accelerated Identity Conflict Resolution
Faster resolution of disputes about identity merges
-20%
Reduction in Debugging Cycles
25-40%%
Faster Identity Conflict Resolution
15-20%
Increase in Modeling Reliability
65-70%
Earlier Detection of Stitching Conflicts
Next Steps & What I’d Do Differently
Future-facing opportunities that leverage the workspace foundation
What I’d Do Next
The following results were measured after the first quarter of GA, demonstrating the success of the “Pipeline Readiness” strategy
Detect Behavioral Drift Before It Impacts Models
Expand behavioral modeling previews and introduce drift comparisons
Simulate Identity Conflicts Before Deployment
Create identity conflict simulation for ML experimentation
Benchmark & Audit Modeled Features at Scale
Integrate with Query Services to audit and benchmark modeled features
Expose Feature Influence on Outcome
Introduce feature importance and compare how event patterns drive outcomes
Surface High-Impact Behavioral Patterns
Add behavioral clustering to surface meaningful user patterns
Standardize Customer-Facing AI Explanations
Provide explanation templates for future customer-facing transparency
Validate Feature Transformations Before Commit
Explore feature generation previews to validate transformations before commit
Related Case Studies
Let’s Work Together
Interested in collaborating on complex UI/UX challenges involving data, AI, or enterprise systems?
I’d love to explore how thoughtful design can drive clarity and business impact.
Get In Touch
About Kelli
Product Designer | AI x Data Systems
Passionate about turning complex data and AI systems into clear, trustworthy, human-centered experiences
Based in: San Francisco, CA
© 2026 Kelli Nordfelt


Overview

Problem

Technical Wall

Design Pivot

System Impact

Next Steps
Profile Modeling and Transparency
Rational Logic Foundations
Establishing the foundational data blueprint for the ecosystem by solving for “confident mistakes” through staged validation and progressive logic
Overview
As Adobe expanded its ML and predictive modeling efforts, internal teams struggled to understand how profiles were stitched, how attributes were derived, and how behavioral events contributed to modeled features. Visibility across these systems was limited. As a result, debugging was slow, inconsistent, and often required heavy engineering involvement.
Internal Tooling Exploration
This work created foundational capabilities that influenced:
- Identity resolution improvements
- Early feature engineering for predictive models
- Behavioral signal quality evaluation
- Early ML-driven segmentation prototypes
- Future plans for customer-facing AI transparency tools
My Role
Primary designer responsible for defining modeling workflows, object-level metadata, quality scoring, validation mechanics, and visualization patterns. This work occurred after GA for core ingestion and schema features and ran in parallel with Query Services and early data modeling initiatives. It became the interpretability layer that tied together object structure, mapped data, and the emerging profile model.
The Problem
Identity was a black box, making behavior modeling slow, inconsistent, and hard to validate
Key Problems
Internal ML and data engineering teams needed to understand why profiles were stitched the way they were, how attributes were generated, and which behavioral events contributed to downstream predictive models. But profile formation logic was opaque, making it difficult to debug model features, evaluate attribute drift, or diagnose segmentation inconsistencies.
Teams struggled to:
- Understand which identifiers contributed to profiles
- Troubleshoot incorrect profile merges/duplicates
- Validate that attributes were complete and reliable
- Trace lineage back to source and ingestion event
Data Lineage Graph
Visualizing the flow from raw data sources to actionable features
Schema decisions define system behavior, not just data structure
Abandonment Rate Ingestion Workflow Stages
80
60
40
20
0
10%
File
Upload
25%
Schema
Mapping
45%
Review
Dataflow
60%
Enable
for Profile
70%+
Final
Ingestion
User Research Insights
- 78% User struggled to validate & resolve across the system
- 35% Abandoned complex ETL tasks
- 42% Satisfied with current workflow
Raw Data
Customer Database
PostgreSQL
Web Analytics
Clickstream data
Mismatch fields
Mobile App Events
Firebase
Offline
Internal data lake
Mismatch fields
Field mapping
Customer Database
PostgreSQL
Web Analytics
Clickstream data
Duplicate IDs
Mobile App Events
Firebase
Offline
Internal data lake
Duplicate IDs
Identity Cluster
Identity Resolution
Email + Device ID
Target Errors
User Profiles
Unified customer view
Anonymous Tracking
Cookie-based IDs
Behavioral Events
Page Views
Navigation patterns
Product Interactions
Clicks, searches
Purchases
Transaction events
Offline
Internal data lake
Modeled Features
Customer LTV
Lifetime value score
Churn Risk
Probability 0-1
Product Affinity
Recommendation scores
Engagement Score
Activity index
Segment & Activation
High-Value Customers
LTV > $10
Warning
Churn Risk Cohort
Risk > 0.7
Warning
Product Affinity
Affinity segments
Warning
Re-engagement Targets
Low engagement score
Warning
The Technical Wall
Creating a shared modeling workspace where identity, attributes, and behavioral signals could be inspected and validated
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Identity rules and stitching behavior
Attribute formation across object relationships
Behavioral event contributions to profile features
Confidence indicators for features and relationships
The goal was to give internal teams a single interpretation layer that improved confidence, debugging speed, and communication across engineering and machine learning groups.
Primary Objectives
- Make identity formation logic understandable and inspectable
- Visualize attribute lineage and behavioral influence paths
- Improve debugging workflows and accelerate model validation
- Reduce reliance on engineering for explanation and troubleshooting
Project Constraints
- Identity logic was evolving across multiple engineering teams
- The interface needed abstraction without oversimplifying the model
- Sensitive metadata required controlled visibility and role alignment
Success Criteria
- Faster internal debugging cycles
- Improved trust in stitched profiles
- Higher reliability of machine learning features
- Clearer lineage and reasoning for behavior-driven signals
The Design Pivot
A cross-functional effort involving data engineering, machine learning, and product teams that connected identity, enrichment, and downstream outcomes
Object Orientation Exploration
Taking inventory of objects and meta data required in a schema and understanding what the user cares about most
Research & Discovery
Internal interviews uncovered a wide range of interpretation and debugging needs
Machine learning teams required clarity into how features were constructed. Data engineers needed to troubleshoot lineage breaks. Product teams needed a way to communicate identity and attribute logic across the organization.
Deliverables
Workshop personal and technical requirements
Identity workflow audit
Behavioral signal mapping
Failure-mode matrix for modeling inputs
Workshops – Personas and Technical requirements
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Data Engineer
“As a data engineer, I need visibility into how my data is moving through pipelines, especially during QA or transformation so I can catch issues early and promote reliable, production-ready datasets with confidence”
Journey Mapping and Storyboarding
Design & Prototyping
I introduced a modeling canvas that supported:
- Identity cluster exploration
- Attribute formation views
- Behavioral lineage diagrams
- Feature stability indicators
- Comparison tools for profile versions
This created a familiar interface while reducing manual effort and increasing correctness.
Deliverables
Dual-pane mapping workspace
Schema preview and glossary integration
Mapping templates and bulk ops
Suggestion layer (confidence and rationale)
Workflow Recommendations and Valid Entry Points
Over the course of three days we focused on:
- Mapped real ingestion workflows with architects and data engineers
- Analyzed abandonment and error data
- Conducted task analysis to find visibility
- Reviewed research/interviews to uncover pain points with subject matter experts to make sure we were considering the crucial constraints
Design System Guidelines
Entity Relationship Diagram (ERD) View Pattern Guidelines
Development & Testing
We evaluated real customer payloads to tune confidence thresholds and rationale messaging. Testing confirmed that explainability mattered more than automation alone. Users trusted suggestions when they understood the “why”
Deliverables
Assisted mapping trust patterns
Identity conflict alerts
Drift detection and notifcations
Low-Fidelity Prototyping
Partnered with Engineering to Refine:
- Validation rules and thresholds
- Drift detection workflows
- Feature reliability scoring
- Comparison tooling for debugging
Launch & Iteration
Stabilizing the modeling workspace and improving interpretability flows
After releasing the initial internal modeling workspace, our iteration focus was on refinement and stabilization. We incorporated feedback from ML and engineering teams to make the interface easier to interpret and to reduce friction in day-to-day debugging.
High-Fidelity Wireframes
System Impact
Improved identity clarity strengthened data quality and modeling reliability
The Validation Strategy: Pipeline over UI
Instead of measuring the success by feature count, we validated the “Pipeline Readiness.” We intentionally deferred advanced UI capabilities to ensure the foundation data “handshake” was unbreakable.
Enabled Scalable AI Transparency
Clearer communication for future customer-facing AI transparency work
Aligned Engineering & ML on Profile logic
A shared understanding of profile formation across engineering and ML
Accelerated Identity Conflict Resolution
Faster resolution of disputes about identity merges
-20%
Reduction in Debugging Cycles
25-40%%
Faster Identity Conflict Resolution
15-20%
Increase in Modeling Reliability
65-70%
Earlier Detection of Stitching Conflicts
Next Steps & What I’d Do Differently
Future-facing opportunities that leverage the workspace foundation
What I’d Do Next
The following results were measured after the first quarter of GA, demonstrating the success of the “Pipeline Readiness” strategy
Detect Behavioral Drift Before It Impacts Models
Expand behavioral modeling previews and introduce drift comparisons
Simulate Identity Conflicts Before Deployment
Create identity conflict simulation for ML experimentation
Benchmark & Audit Modeled Features at Scale
Integrate with Query Services to audit and benchmark modeled features
Expose Feature Influence on Outcome
Introduce feature importance and compare how event patterns drive outcomes
Surface High-Impact Behavioral Patterns
Add behavioral clustering to surface meaningful user patterns
Standardize Customer-Facing AI Explanations
Provide explanation templates for future customer-facing transparency
Validate Feature Transformations Before Commit
Explore feature generation previews to validate transformations before commit
Related Case Studies
Let’s Work Together
Interested in collaborating on complex UI/UX challenges involving data, AI, or enterprise systems?
I’d love to explore how thoughtful design can drive clarity and business impact.

Get In Touch

About Kelli
Product Designer | AI x Data Systems
Passionate about turning complex data and AI systems into clear, trustworthy, human-centered experiences
Based in: San Francisco, CA
© 2026 Kelli Nordfelt